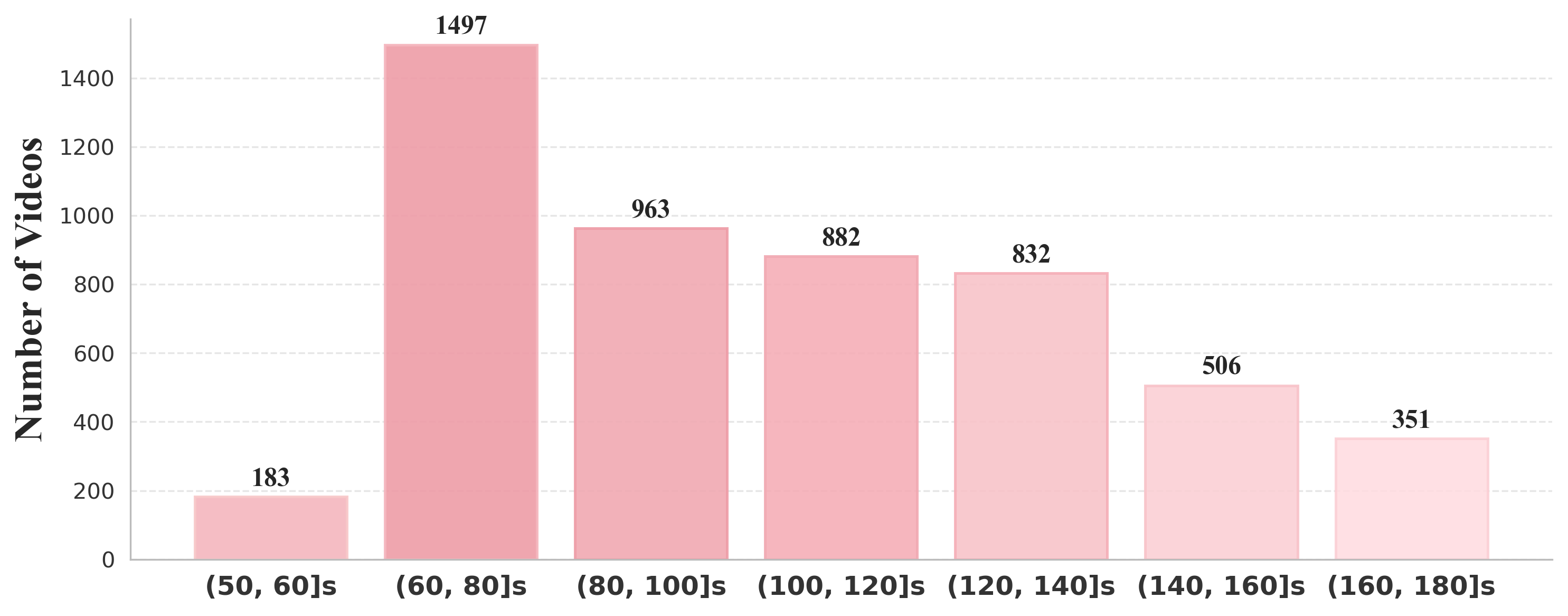
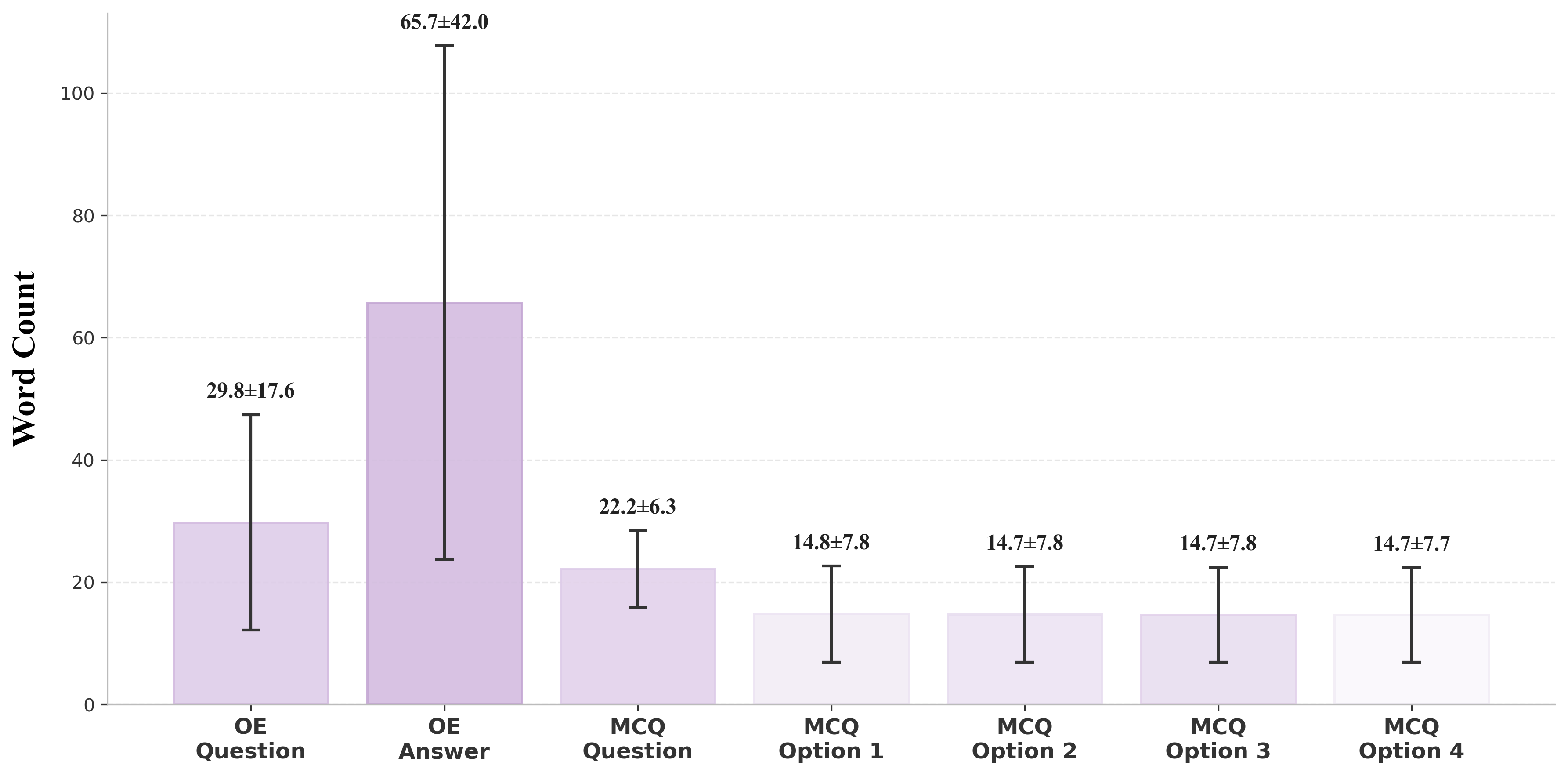
Method
Entity-Anchored Scripts & Clue-Guided QA
The pipeline formalizes the raw video into a structured text representation, enabling LLMs to mine evidence chains before QA synthesis.
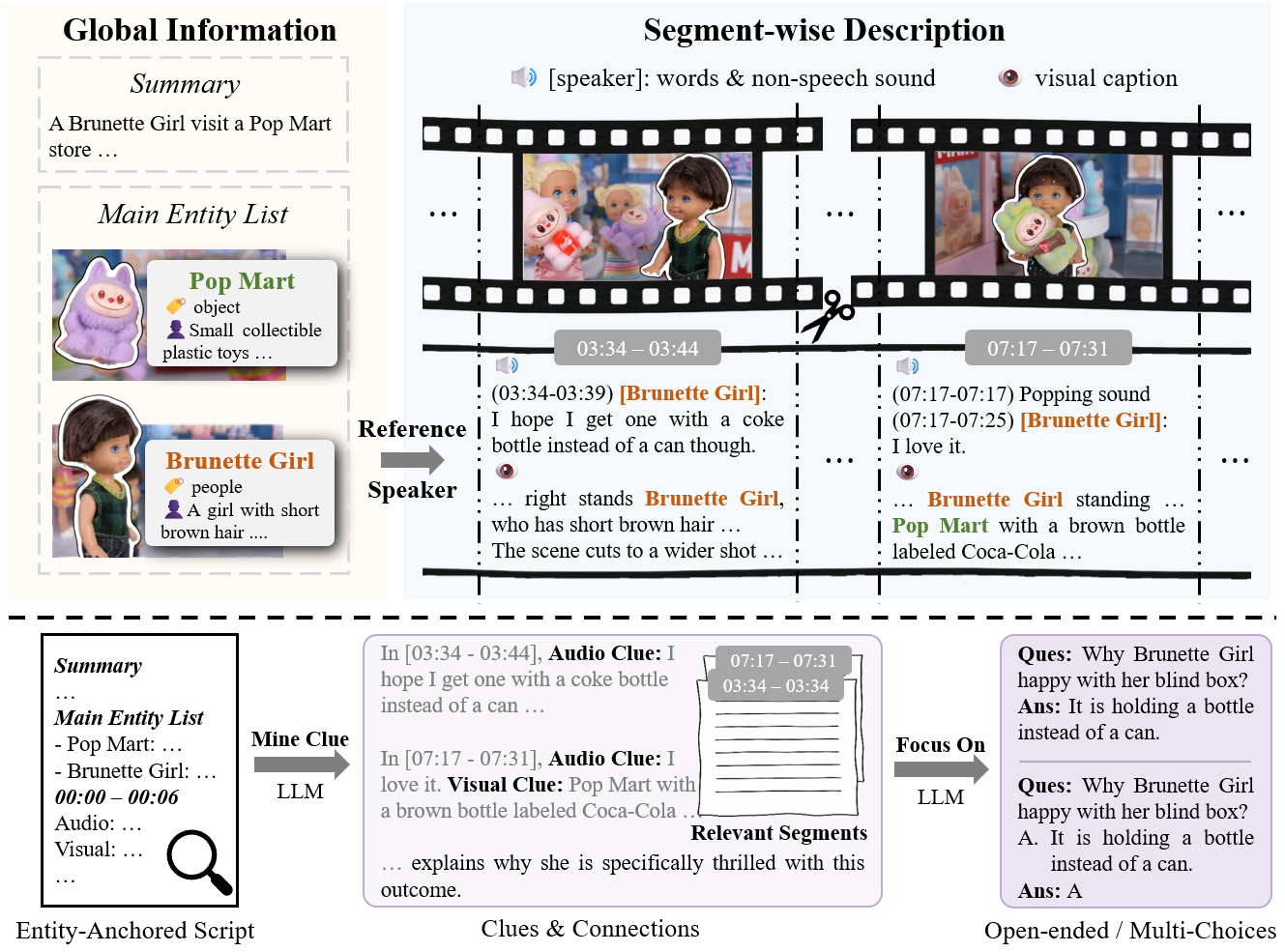
Entity-Anchored Video Scripting
Script: a summary, a main entity list, and structured segment-wise descriptions that integrate speech, sounds, and visual information.
Use consistent identifiers (orange and green text) from the main entity list to ensure coherence across clips and associate speech with visual entities.
Clue-Guided QA Generation
Mine cross-segment and cross-modal clues from the script.
Produce QA pairs based on the clues and relevant segments.
Why is Brunette Girl happy with her blind box?
Earlier [03:34 - 03:44], another person is shown holding a Pop Mart doll that carries a red soda can. Later [07:17 - 07:31], the scene shows the Brunette Girl holding her own newly unboxed doll, which carries a brown soda bottle labeled Coca-Cola.
At [03:34 - 03:39], upon seeing another doll being shown, Brunette Girl expresses her expectation: "I hope I get one with a coke bottle instead of a can though." Later, at [07:17 - 07:25], she opens her own blind box and happily exclaims: "I love it."
It is holding a bottle instead of a can.